Qwen-Image-2512
The Strongest Open-Source
Text-to-Image AI Model
Qwen-Image-2512 delivers unprecedented realism with enhanced human detail rendering, finer natural textures, and superior text generation capabilities. Experience the most advanced open-source text-to-image model available today.
Core Features of Qwen-Image-2512
Revolutionary text-to-image generation technology with unprecedented realism and detail
Enhanced Human Realism
Qwen-Image-2512 significantly reduces the "AI-generated" look with improved facial detail and realism. Generate human portraits with natural expressions, accurate skin textures, and lifelike environmental context that rivals professional photography.
Finer Natural Details
Experience detailed landscape rendering with Qwen-Image-2512. Precise animal fur and texture depiction, enhanced water reflections, realistic foliage, and natural elements that bring your creative vision to life with stunning accuracy.
Improved Text Rendering
Qwen-Image-2512 delivers better accuracy and quality of textual elements within generated images. Create infographics, posters, and educational content with precise text layout and composition that maintains readability and visual appeal.
Multiple Aspect Ratios
Qwen-Image-2512 supports 7 different aspect ratios including 1:1, 16:9, 9:16, 4:3, 3:4, 3:2, and 2:3. Generate images optimized for social media, presentations, mobile devices, or any creative project with flexible dimension control.
Strongest Open-Source Model
Based on 10,000+ blind model evaluations on AI Arena, Qwen-Image-2512 is the strongest open-source text-to-image model available. Highly competitive with closed-source models while maintaining complete transparency and accessibility.
Open Source & Apache 2.0
Fully open-source under Apache 2.0 license. Integrate Qwen-Image-2512 into your projects with complete freedom. Access the model weights, code, and documentation to build innovative applications without restrictions.
Core Technical Innovations of Qwen-Image-2512
Revolutionary breakthroughs that make Qwen-Image-2512 the strongest open-source text-to-image model
Advanced Diffusion Architecture
Qwen-Image-2512 employs a state-of-the-art diffusion model architecture optimized for photorealistic image generation. Unlike previous iterations, the model features enhanced denoising capabilities that significantly reduce the "AI-generated" appearance common in synthetic images.
- 50 inference steps recommended for optimal quality (configurable from 20-100 steps)
- True CFG scale of 4.0 for balanced creativity and prompt adherence
- Support for bfloat16 precision on GPU for efficient memory usage
Enhanced Human Realism Engine
Qwen-Image-2512 introduces breakthrough improvements in human portrait generation, addressing the common "plastic" or "overly smooth" skin texture issues found in competing models. The model achieves this through specialized training on diverse human facial features and skin textures.
- Natural skin texture rendering with pores, wrinkles, and imperfections
- Accurate facial feature proportions and expressions
- Realistic lighting and shadow interaction on human subjects
Superior Text Rendering Technology
One of Qwen-Image-2512's standout features is its exceptional ability to generate accurate, readable text within images. This capability surpasses most competing models.
- Accurate spelling and font rendering in multiple languages
- Proper text layout and composition within complex scenes
Stable LoRA Training Framework
Qwen-Image-2512 features significantly improved LoRA training stability compared to previous versions. This makes custom model fine-tuning more accessible.
- Gradual training progression without sudden jumps
- Effective results even with lower-quality datasets
Qwen-Image Model Evolution
Complete timeline of Qwen-Image model family - August 2025 to December 2025
Model Release Timeline
Qwen-Image-2512
Released: December 31, 2025
- • More realistic humans
- • Enhanced texture quality
- • Stronger text rendering
- • Strongest open-source model on AI Arena
Qwen-Image-Edit-2511
Released: December 23, 2025
- • Multiple image support
- • Improved consistency
- • Better layout and text-image composition
Qwen-Image-Layered
Released: December 19, 2025
- • Layered image generation capabilities
Qwen-Image-Edit-2509
Released: September 22, 2025
- • Multiple image support
- • Improved consistency over Edit version
- • Enhanced instruction following
Qwen-Image-Edit
Released: August 18, 2025
- • Image editing capabilities
- • Single image input support
Qwen-Image
Released: August 4, 2025
- • 20B MMDiT foundation model
- • Complex text rendering
- • Precise image editing
What's New in Qwen-Image-2512
More Realistic Humans
Qwen-Image-2512 delivers significantly improved human portrait generation with enhanced facial details and natural appearance.
Enhanced Texture Quality
Improved rendering of textures across all image types, from natural landscapes to detailed materials.
Stronger Text Rendering
Superior text generation capabilities with better accuracy and integration within images.
AI Arena Champion
Ranked as the strongest open-source image model on AI Arena based on extensive blind evaluations.
Model Family Overview
Qwen-Image-2512 represents the latest advancement in text-to-image generation, focusing on photorealistic output with enhanced human realism and texture quality.
The Edit series (Qwen-Image-Edit, Edit-2509, Edit-2511) specializes in image editing capabilities with progressive improvements in multi-image support and consistency.
Qwen-Image-Layered introduces layered generation capabilities for more complex image composition workflows.
All models are built on the Qwen-Image foundation (20B MMDiT architecture) and are open-source under Apache 2.0 license.
Qwen-Image-2512 vs Previous Models: Visual Comparison
See the dramatic improvements in image quality, human realism, and natural details
Enhanced Human Realism
More natural facial features, better skin textures, and realistic expressions

Chinese female college student - Natural dormitory selfie with realistic lighting

East Asian girl at anime convention - Enhanced facial detail and natural expressions
Finer Natural Details
Superior landscape rendering, animal fur textures, and water reflections

Turquoise river canyon - Enhanced water reflections and rock textures

Golden Retriever portrait - Individual fur strands and realistic textures
Improved Text Rendering
Accurate text layout, better spelling, and seamless text-image integration

Development roadmap - Complex timeline with accurate text rendering

Educational poster - 12-panel grid with precise text layout
AI Arena Performance
Strongest open-source model based on 10,000+ blind evaluations
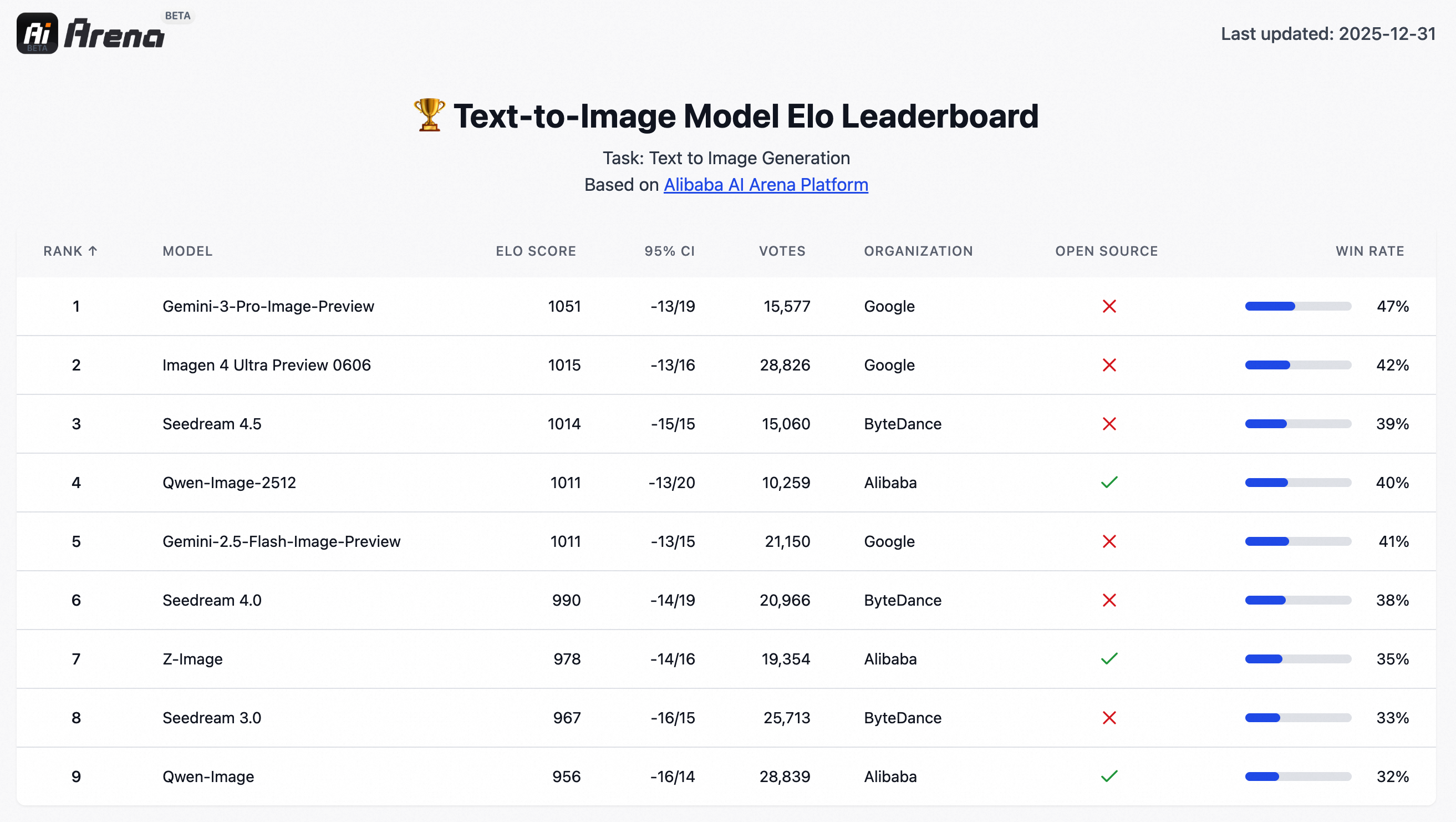
Qwen-Image-2512 ranks as the strongest open-source text-to-image model, competitive with leading closed-source models like Google's Imagen 4 Ultra and Gemini 3 Pro.
Qwen-Image-2512 vs Original Qwen-Image
| Feature | Qwen-Image-2512 | Qwen-Image (Aug 2025) |
|---|---|---|
| Human Realism |
Dramatically reduced "AI look"
Natural skin textures, individual hair strands, age-appropriate features |
Basic human generation
Noticeable "AI-generated" appearance, smoother textures |
| Natural Textures |
Enhanced detail rendering
Superior water reflections, animal fur, landscape details |
Standard texture quality
Good but less refined natural elements |
| Text Rendering |
Superior accuracy
Better spelling, layout, and text-image composition |
Good text rendering
Complex text rendering capability |
| Model Size | Large-scale diffusion model | Large-scale diffusion model |
| Release Date | December 31, 2025 | August 4, 2025 |
| AI Arena Ranking |
#1 Open-Source Model
|
Strong foundation model |
Qwen-Image-2512 vs Z-Image-Turbo
Qwen-Image-2512
- 20B parameters - Larger model for superior quality
- Enhanced realism - Dramatically reduced "AI look"
- Open-source - Apache 2.0 license
- AI Arena #1 - Strongest open-source model
- 50 steps - Higher quality, longer generation
Z-Image-Turbo
- 6B parameters - Compact and efficient
- Sub-second speed - Lightning-fast generation
- 16GB VRAM - Consumer hardware friendly
- Photorealistic - Strong HDR-like effects
- 8 NFEs - Optimized for speed
| Aspect | Qwen-Image-2512 | Z-Image-Turbo |
|---|---|---|
| Primary Focus | Maximum quality & realism | Speed & efficiency |
| Model Size | 20B parameters | 6B parameters |
| Generation Speed | Standard generation time | Sub-second (8 NFEs) |
| VRAM Requirement | CUDA-compatible GPU recommended | 16GB (consumer friendly) |
| License | Open-source (Apache 2.0) | Proprietary |
| Prompting | Standard positive/negative | Positive only (no negative prompts) |
| Best Use Case | Production-quality images, detailed work | Rapid prototyping, real-time generation |
Key Insight: Qwen-Image-2512 prioritizes maximum quality and realism with its larger large-scale architecture, while Z-Image-Turbo focuses on lightning-fast generation with a compact 6B model. Both excel in their respective domains.
Qwen-Image-2512 vs Competing Models
Comprehensive comparison with FLUX, Stable Diffusion, and Z-Image-Turbo
Qwen-Image-2512 Strengths
- • Superior text rendering accuracy
- • Excellent prompt adherence and diversity
- • Stable LoRA training (casual-friendly)
- • Strong cinematic and environmental generation
- • Open-source with Apache 2.0 license
Known Limitations
- • May produce slight "plastic" look in some cases
- • Higher quality generation
- • Requires CUDA-compatible GPU for optimal performance
- • Occasional gender inconsistency in portraits
Qwen-Image-2512 vs FLUX
While FLUX excels in consistency and seamless element integration, Qwen-Image-2512 offers superior prompt adherence and text rendering. FLUX may produce more variation in human portraits but can exhibit the "Flux chin" issue.
Qwen-Image-2512 vs Stable Diffusion
Stable Diffusion (SDXL, SD3) remains a strong foundation model. Qwen-Image-2512 surpasses it in human realism, text accuracy, and out-of-the-box quality, though SD benefits from extensive LoRA ecosystem.
Qwen-Image-2512 vs Z-Image-Turbo
Z-Image-Turbo offers faster generation with fewer steps and strong photorealism. However, Qwen-Image-2512 provides better prompt diversity, text rendering, and is fully open-source (ZIT is not).
Qwen-Image-2512 Showcase & Use Cases
Discover how Qwen-Image-2512 transforms creative workflows across industries
Digital Art Creation
Qwen-Image-2512 enables artists to generate stunning digital artwork with unprecedented realism. Create concept art, illustrations, and visual designs with enhanced human detail and natural textures.
Marketing & Advertising
Use Qwen-Image-2512 to create compelling marketing visuals, social media content, and advertising materials. Generate campaign images with accurate text rendering and professional quality.
Educational Content
Qwen-Image-2512 helps educators create engaging visual materials, infographics, and educational illustrations with precise text rendering and clear visual communication.
E-commerce
Generate product visualization and lifestyle images with Qwen-Image-2512. Create multiple product variations and marketing materials efficiently for online stores.
Game Development
Qwen-Image-2512 assists game developers in creating concept art, character designs, and environmental assets with realistic details and consistent quality.
Content Creation
Content creators use Qwen-Image-2512 to generate thumbnails, social media posts, and visual content for blogs, videos, and digital publications with professional quality.
Quick Start Guide for Qwen-Image-2512
Get started with Qwen-Image-2512 in minutes - Complete installation and usage guide
Installing Qwen-Image-2512
Install Qwen-Image-2512 and its dependencies:
pip install git+https://github.com/huggingface/diffusers
pip install transformers accelerate safetensors
Basic Usage of Qwen-Image-2512
Generate images with Qwen-Image-2512:
from diffusers import DiffusionPipeline
import torch
# Load Qwen-Image-2512 pipeline
pipe = DiffusionPipeline.from_pretrained(
"Qwen/Qwen-Image-2512",
torch_dtype=torch.bfloat16
).to("cuda")
# Generate image with Qwen-Image-2512
prompt = "A realistic portrait of a person"
image = pipe(
prompt=prompt,
width=1664,
height=928,
num_inference_steps=50,
true_cfg_scale=4.0
).images[0]
image.save("output.png")
Qwen-Image-2512 Resources
Frequently Asked Questions About Qwen-Image-2512
Everything you need to know about Qwen-Image-2512 text-to-image generation
Qwen-Image-2512 is an advanced open-source text-to-image AI model that generates high-quality images from text descriptions. It uses diffusion technology to create realistic images with enhanced human detail, finer natural textures, and improved text rendering capabilities. Qwen-Image-2512 is the strongest open-source model based on 10,000+ blind evaluations on AI Arena.
Qwen-Image-2512 supports 7 different aspect ratios: 1:1 (1328x1328), 16:9 (1664x928), 9:16 (928x1664), 4:3 (1472x1104), 3:4 (1104x1472), 3:2 (1584x1056), and 2:3 (1056x1584). This flexibility allows you to generate images optimized for various platforms and use cases.
Yes! Qwen-Image-2512 is licensed under Apache 2.0, which allows for both personal and commercial use. You can integrate Qwen-Image-2512 into your projects, modify the code, and distribute it freely without licensing fees or restrictions.
Qwen-Image-2512 requires a CUDA-compatible GPU for optimal performance. Recommended specifications include: NVIDIA GPU with 8GB+ VRAM, Python 3.8+, PyTorch 2.0+, and the latest diffusers library. For best results, use bfloat16 precision on GPU or float32 on CPU.
Qwen-Image-2512 is the strongest open-source text-to-image model based on 10,000+ blind evaluations. It excels in prompt adherence, text rendering, and LoRA training stability. Compared to FLUX, it offers better text accuracy; compared to Z-Image-Turbo, it's fully open-source with superior prompt diversity.
While Qwen-Image-2512 significantly reduces the "AI-generated" appearance, some users may still notice slight smoothness in certain scenarios. This is a common challenge across all AI image models. Adjusting inference steps (40-50 recommended) and using appropriate prompts can help achieve more natural results.
Qwen-Image-2512 features much more stable LoRA training compared to previous versions. Training progresses gradually without sudden jumps to overtraining, making it "casual friendly" and effective even with lower-quality training data. This is a major improvement reported by the community.
Qwen-Image-2512 works best with 10GB+ VRAM. Users with limited VRAM may encounter "Ran out of memory when regular VAE decoding" warnings, which triggers tiled VAE decoding as a fallback. For optimal performance, use bfloat16 precision on GPU.