
简介
2026 年 1 月,阿里巴巴 Qwen 团队推出了 Qwen3-TTS,一个真正令人印象深刻的开源文本转语音模型。如果你想了解它的工作原理——从技术规格到实际使用方法——这份指南将为你提供全面的信息。
什么是 Qwen3-TTS?
Qwen3-TTS 是一个真正跨语言工作的文本转语音模型。它是开源的(Apache 2.0 许可证),在 500 多万小时的语音数据上进行了训练,有两个版本可供选择:
- 1.7B 版本:功能完整的模型。质量更好,需要更多 GPU 功率(6-8GB VRAM)
- 0.6B 版本:轻量级选项。质量仍然不错,可在功能较弱的硬件上运行(4-6GB VRAM)
两个版本都可在 Hugging Face 和 GitHub 上获得。1.7B 占用 4.54GB,0.6B 占用 2.52GB。
Qwen3-TTS 模型规格和参数
模型变体对比
| 方面 | 1.7B 模型 | 0.6B 模型 |
|---|---|---|
| 参数数量 | 17 亿 | 6 亿 |
| 存储大小 | 4.54 GB | 2.52 GB |
| 所需 VRAM | 6-8 GB | 4-6 GB |
| 性能 | 峰值质量 | 平衡效率 |
| 使用场景 | 生产、高质量 | 演示、资源受限 |
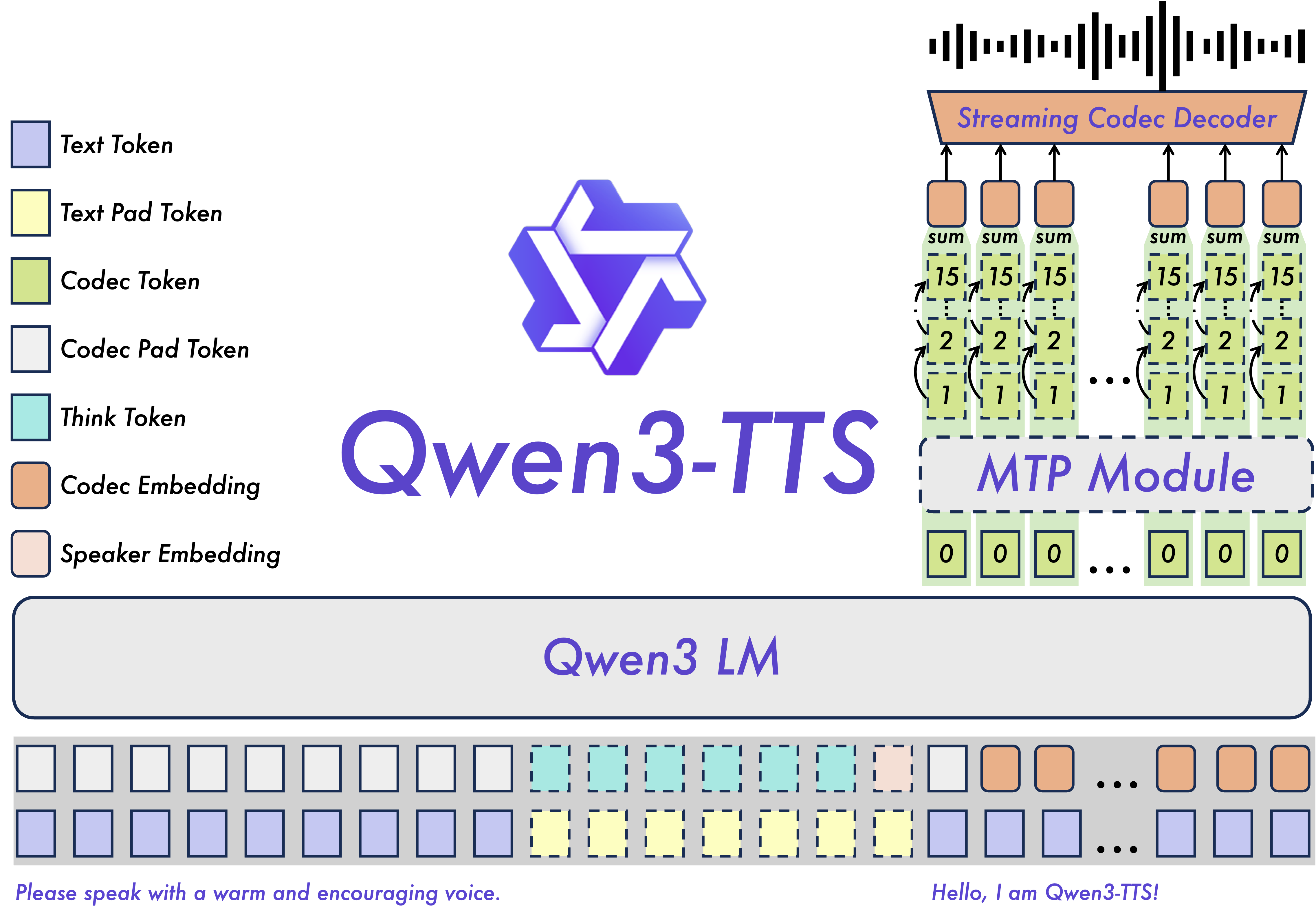
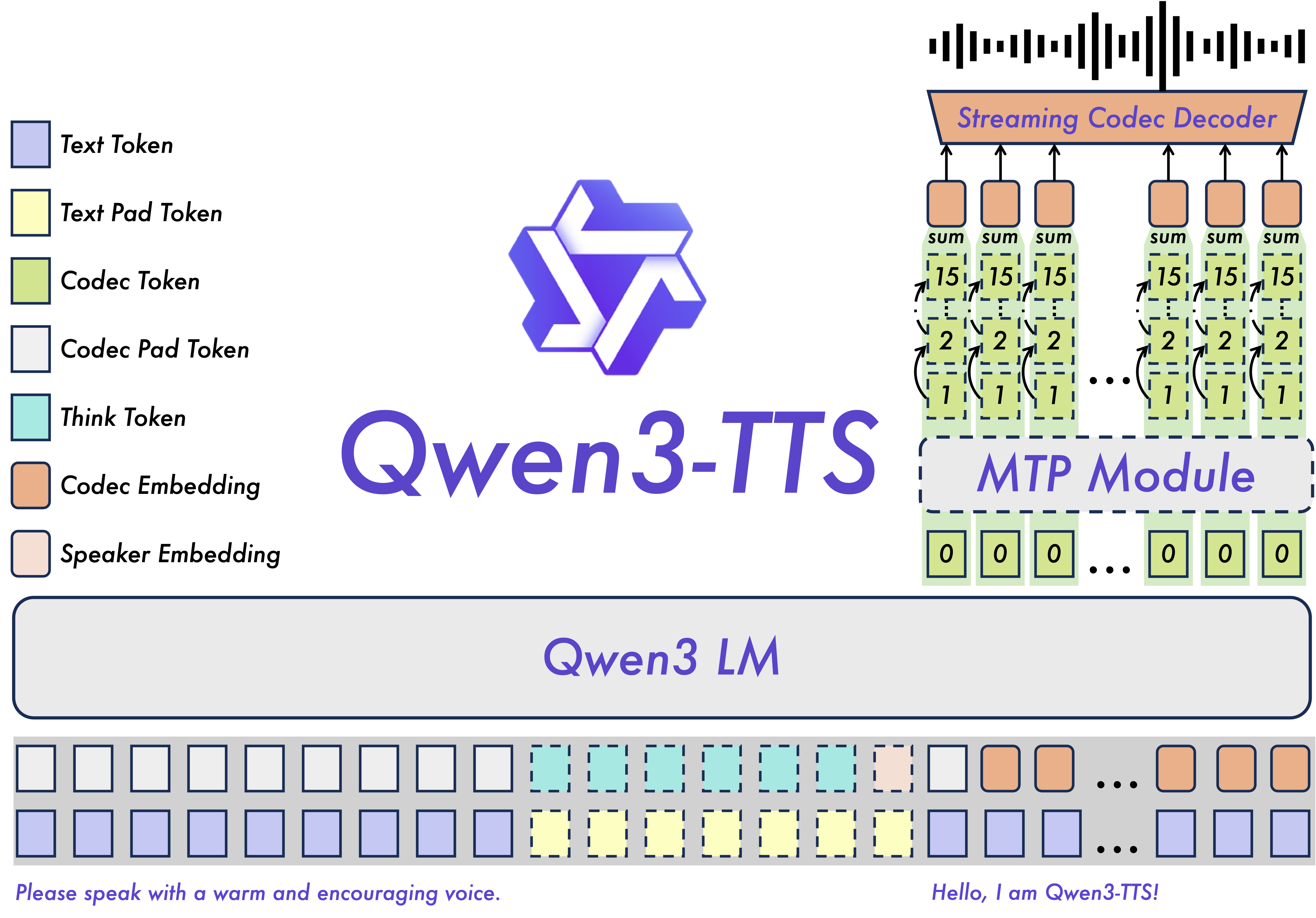
秘密武器:Qwen3-TTS-Tokenizer-12Hz
在底层,Qwen3-TTS 使用自定义分词器来压缩语音而不损失质量。以下是其性能表现:
- STOI:0.96(可理解性几乎完美)
- UTMOS:4.16(听起来自然)
- 说话人相似度:0.95(保持你的声音特征)
- PESQ 宽带:3.21
- PESQ 窄带:3.68
总结:音频质量几乎无损。模型压缩语音时不会丢失太多信息。
Qwen3-TTS 硬件要求
GPU 和 VRAM 要求
对于 Qwen3-TTS-1.7B 模型:
- 最小 VRAM:6 GB
- 推荐 VRAM:8 GB
- 最优 VRAM:12+ GB
对于 Qwen3-TTS-0.6B 模型:
- 最小 VRAM:4 GB
- 推荐 VRAM:6 GB
- 最优 VRAM:8+ GB
推荐的 GPU 硬件
- 入门级:NVIDIA GTX 1070 或同等产品(8 GB VRAM)
- 中端:NVIDIA RTX 3060 或更高(12 GB VRAM)
- 生产级:NVIDIA RTX 4080 或 A100(16+ GB VRAM)
系统要求
- Python:3.8 或更高版本
- CUDA:支持 CUDA 的兼容 GPU
- 存储:3-5 GB 用于模型权重
- RAM:推荐 16 GB+ 系统内存
性能优化
要减少 GPU 内存使用并提高性能:
- FlashAttention 2:推荐用于以
torch.float16或torch.bfloat16加载的模型 - 量化:GPTQ-Int8 可将内存占用减少 50-70%
- 批处理:针对你的硬件优化批大小
Qwen3-TTS 的五大核心功能
1. 自然语言语音设计
使用自然语言描述创建自定义语音。指定:
- 音色特征:"深沉的男性声音"或"明亮的女性声音"
- 韵律控制:"缓慢说话并强调"或"快速节奏充满活力的表达"
- 情感语调:"温暖友好"或"专业权威"
- 人物属性:"年轻的科技爱好者"或"经验丰富的叙述者"
2. 3 秒语音克隆
Qwen3-TTS-VC-Flash 支持从仅 3 秒音频输入进行快速语音克隆:
- 克隆任何语音用于个性化应用
- 在所有内容中保持一致的语音
- 为失去语音能力的个人创建语音
- 跨多种语言本地化内容
3. 超低延迟流式传输
双轨混合流式生成架构支持:
- 首包延迟:低至 97ms
- 端到端合成延迟:实时应用下 100ms 以内
- 适合对话 AI、实时翻译和交互式语音应用
4. 多语言支持(10 种语言)
Qwen3-TTS 支持 10 种主要语言,具有接近本地人的质量:
- 中文 - 普通话和多种方言
- 英文 - 美式、英式和国际变体
- 日语 - 自然的韵律和语调
- 韩语 - 准确的发音和节奏
- 德语 - 精确的发音
- 法语 - 真实的口音和连读
- 俄语 - 复杂的音素处理
- 葡萄牙语 - 巴西和欧洲变体
- 西班牙语 - 拉丁美洲和欧洲西班牙语
- 意大利语 - 区域口音支持
5. 49+ 高质量语音音色
Qwen3-TTS 提供 49 多种专业制作的语音音色:
- 性别多样性:男性、女性和中性语音
- 年龄范围:从年轻成人到老年人
- 角色档案:专业、随意、充满活力、平静、权威
- 情感范围:快乐、悲伤、愤怒、中立、兴奋
- 区域特征:各种口音和说话风格
Qwen3-TTS 性能基准
多语言词错误率(WER)
Qwen3-TTS 在多种语言中实现了最先进的性能:
| 语言 | Qwen3-TTS WER | 性能 |
|---|---|---|
| 平均(10 种语言) | 1.835% | 业界最佳 |
| 英文 | 有竞争力 | 本地人水平 |
| 中文 | 业界领先 | 卓越准确度 |
| 意大利语 | 业界最佳 | 异常出色 |
| 法语 | 优越 | 超越竞争对手 |
说话人相似度得分
- 10 种语言平均值:0.789
- 超越:MiniMax 和 ElevenLabs
- 跨语言适应性:异常出色
长形式生成稳定性
- 能够合成 10+ 分钟的自然流畅语音
- 长音频上没有质量下降
- 保持一致的说话人特征
安装和快速开始
安装步骤
从基础开始:
pip install transformers torch然后克隆仓库并安装依赖项:
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
pip install -r requirements.txt想要更好的性能?添加 FlashAttention 2:
pip install -U flash-attn --no-build-isolation基本使用示例
from qwen_tts import Qwen3TTSModel
import soundfile as sf
# 加载模型
model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice")
# 使用自定义语音生成语音
wavs, sr = model.generate_custom_voice(
text="Hello, this is Qwen3-TTS speaking.",
language="English",
speaker="Ryan"
)
# 保存音频
sf.write("output.wav", wavs[0], sr)语音克隆示例
from qwen_tts import Qwen3TTSModel
# 加载用于语音克隆的基础模型
model = Qwen3TTSModel.from_pretrained("Qwen/Qwen3-TTS-12Hz-1.7B-Base")
# 从 3 秒音频样本克隆语音
wavs, sr = model.generate_voice_clone(
text="Your text here",
voice_sample_path="voice_sample.wav",
language="English"
)Qwen3-TTS 的实际应用
内容创建和媒体制作
- 有声书叙述:用于角色对话的多个语音
- 播客制作:整个剧集中的一致语音
- 视频配音:多语言内容本地化
- 电子学习:多种语言的引人入胜的教育内容
对话 AI 和虚拟助手
- 客户服务机器人:自然发音的自动化支持
- 语音助手:个性化的语音交互
- 交互式 IVR 系统:增强的来电者体验
- 智能家居设备:多语言语音控制
无障碍解决方案
- 屏幕阅读器:增强视障用户的无障碍性
- 通信辅助:为言语障碍者恢复语音
- 语言学习:使用本地人语音进行发音练习
- 翻译服务:具有自然语音的实时多语言翻译
游戏和娱乐
- 角色语音:动态 NPC 对话生成
- 交互式故事讲述:自适应叙事体验
- 虚拟影响者:跨平台的一致品牌语音
- 元宇宙应用:逼真的化身语音
Qwen3-TTS 与竞争对手对比
综合对比
| 功能 | Qwen3-TTS | GPT-4o Audio | ElevenLabs |
|---|---|---|---|
| 开源 | ✅ Apache 2.0 | ❌ 专有 | ❌ 专有 |
| 语言 | 10 种主要语言 | 多语言 | 5000+ 语音 |
| 语音音色 | 49+ 语音 | 多个语音 | 5000+ 语音 |
| 语音克隆 | 3 秒快速克隆 | 可用 | 高质量克隆 |
| 首包延迟 | 97ms | 低 | 变化 |
| WER 性能 | 最先进 | 有竞争力 | 良好 |
| 定价 | 免费(自托管) | $0.015/分钟 | 高级定价 |
| 情感控制 | 自然语言指令 | 情感控制功能 | 无与伦比的深度 |
Qwen3-TTS 的主要优势
1. 成本效益
- 开源模型消除许可费用
- 自托管选项以完全控制成本
- API 定价与商业替代品具有竞争力
2. 多语言卓越
- 跨多种语言的卓越 WER 得分
- 广泛的中文方言支持,竞争对手无法匹敌
- 多语言内容的自然代码切换
3. 自定义自由
- 完整的模型访问权限以进行微调
- 无限制的语音克隆
- 自定义应用程序的集成灵活性
4. 低延迟性能
- 97ms 首包延迟用于实时应用
- 用于交互式体验的流式生成
- 针对对话 AI 用例进行了优化
关于 Qwen3-TTS 的常见问题
我可以商业使用 Qwen3-TTS 吗?
可以!Qwen3-TTS 在 Apache 2.0 许可证下发布,允许商业使用。你可以在没有许可费用的情况下将其用于商业应用。
1.7B 和 0.6B 模型有什么区别?
1.7B 模型提供峰值性能和质量,而 0.6B 模型更轻量级,适合资源受限的环境。根据你的硬件能力和质量要求进行选择。
我需要多少 VRAM?
- 0.6B 模型:最少 4-6 GB VRAM
- 1.7B 模型:最少 6-8 GB VRAM
- 推荐:12+ GB 以获得最佳性能
我可以微调 Qwen3-TTS 吗?
可以,Qwen3-TTS 的开源性质允许在自定义数据集上进行微调。这使你能够为特定用例或语言创建专门的模型。
结论
Qwen3-TTS 代表了开源文本转语音技术的重要里程碑。凭借其卓越的多语言性能、广泛的语音选项、超低延迟和强大的语音克隆功能,它提供了对专有解决方案的有力替代方案。
该模型在 Apache 2.0 许可证下的开源性质使最先进的 TTS 技术民主化,使开发人员、研究人员和企业能够在没有许可限制的情况下构建创新的语音应用程序。
无论你是在创建有声书、构建对话 AI 还是开发无障碍解决方案,Qwen3-TTS 都提供了在 2026 年及以后成功所需的工具和灵活性。
资源和链接
- 官方博客:Qwen3-TTS 公告
- GitHub 仓库:QwenLM/Qwen3-TTS
- Hugging Face 模型:Qwen/Qwen3-TTS-12Hz-1.7B-Base
- 文档:Qwen AI 文档
- 社区:Qwen Discord 和 GitHub 讨论